はじめに
この記事は、Fediverse Advent Calendar 2022の21日目の記事です。
Mastodonサーバーの一つである「あすてろいどん」の鯖管のsublimerです。
あすてろいどんは比較的小規模なサーバーで、特にテーマなどは決めていないいわゆる汎用鯖なので、のんびりとマストドンを使ってみたい人におすすめです。
新規登録は大歓迎ですので、気になった方はアカウント登録をしてみてください。
今回は、あすてろいどんの実行基盤をDocker ComposeからKubernetesに移してみた話を書こうと思います。
Docker Compose時代のインフラ構成
Docker Composeを利用していた頃のインフラ構成は、以下の図のようになっていました。
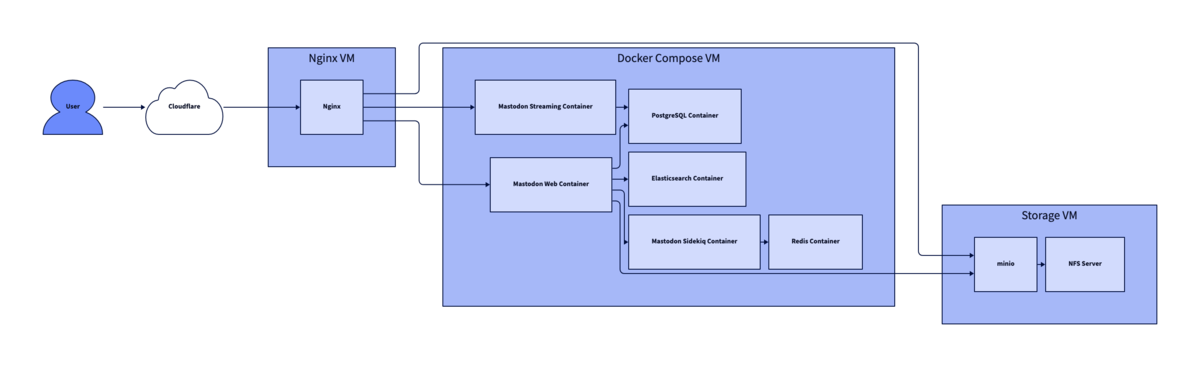
NginxとS3互換でOSSのオブジェクトストレージであるminioはそれぞれ別のVMに載せ、他のアプリケーションはすべて単一のVMでDocker Composeを使って動かしていました。
監視周りは、インターネット、及びVM内からのHTTPの死活監視と、mackerelを用いてコンテナが起動しているかどうかを見ていました。
アプリケーションログは特に何もしておらず、コンテナを再起動するたびに吹き飛ばしていました。
Kubernetes上への移行までの流れ
今回は極力停止時間を少なくしたかったため、Kubernetesの環境が整うまでの間、クラウドサービス上でMastodonを動かすことにしました。
就職してからは業務でGCPを使う機会が非常に増えたので、一時的にGCP上で動かすことにしました。
GCPには90日間、$300分の無料トライアル枠があり、これはまだ使っていなかったのでこの枠を使うことにしました。
GCEにe2-mediumのVMを2つ建て、片方でMastodonを、もう片方でPostgreSQLとRedisを動かすことにしました。
GCPへの移行の際は、先にPostgreSQLを動かして、自宅サーバーのPostgreSQLとの間でレプリケーションの設定を追加しました。
データの同期は、GCEのVMにSSHをつなぎ、ポートフォワードすることでいい感じにデータを流せるようにしました。
PostgreSQLのレプリケーションができたあとは、PostgreSQLのpromoteを実行し、RedisのダンプをGCEに持っていって動かし、DNSのレコードの向き先をGCEに向けて移行完了です。
移行ができたら、あとは自宅サーバーでKubernetesのセットアップを行い、Kubernetes上でMastodonを動かすだけです。
Kubernetes上でMastodonが動かせたら、あとはGCPに移行したときと同じような手順で自宅サーバーに向き先を向ければOKです。
現在のKubernetesを用いたインフラ構成
現在のインフラ構成は、以下の図のようになっています。
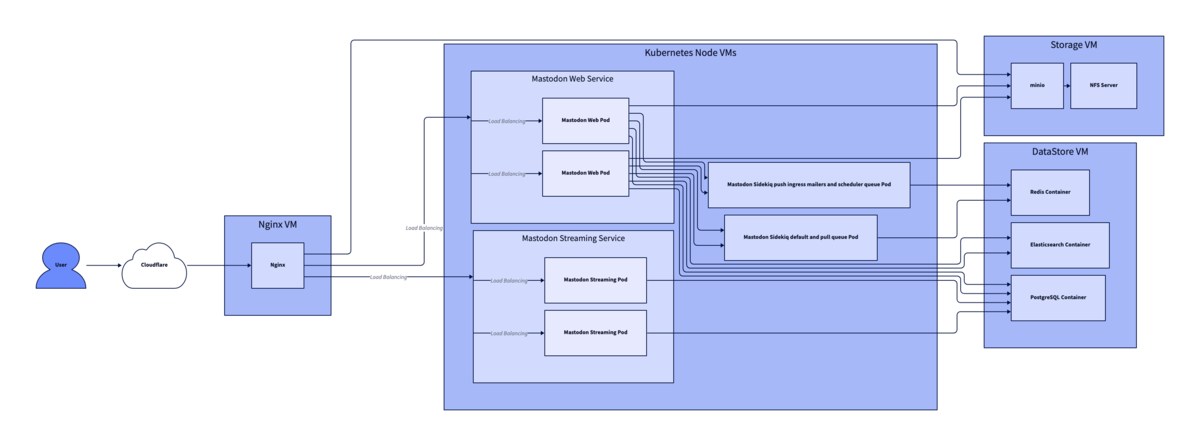
NginxとminioのVMはそのままとし、Docker Composeを使っていた箇所をKubernetesとデータ永続化用のVMに分けた構成になっています。
Kubernetesクラスターはmicrok8sを用いて構成しており、Node数は3つです。
各Nodeは4 Core CPU、 8GB RAMのスペックのVMで動かしているため、リソースにはかなり余裕がある状況です。
MastodonのwebとstreamingのPodはそれぞれLoadbalancer typeのService配下に置いており、リバースプロキシとして動かしているNginxと合わせて負荷分散を行います。
また、SidekiqのPodは default、pullのキューを担当するPodとpush、ingress、mailers、schedulerのキューを担当するPodに分けて配置しています。
SidekiqのPodをキューごとに分けたのは、schedulerのキューを担当するPodは全体で1つにする必要があるためです。schedulerキューでは定期実行されるバッチ処理が実行されるため、複数のPodでschedulerキューを動かしてしまうと、同時実行されてしまう可能性があります。
Kubernetes上でPostgreSQLやRedis、Elasticsearchといった状態を持つアプリケーションを動かす際には工夫が必要となるため、一旦これらのアプリケーションは別VMでDocker Composeを使って動かしています。
将来的にはこれらのアプリケーションもKubernetes上で実行し、完全にKubernetes化ができればいいなと思っています。
システムの監視周りは、Datadogを導入して監視を行うことにしました。
DatadogのAgentもKubernetes上で動かしており、これでPod、Service、Nodeなど、Kubernetesのすべてのリソースを監視しています。
Kubernetesに移行してみて
移行後は、運用や監視が楽になったなーと思います。
特にKubernetesのCronJobは便利ですね。
Mastodonはリモートのメディアをキャッシュとして保持する仕様になっているのですが、これを放置しているとどんどんストレージの使用量が増えていきます。
Docker Composeを使っていたときは気が向いたときに手動で削除していたのですが、Kubernetesに移行してからはCronJobを使って毎日削除するようにしています。
CronJobでリモートのメディアを削除する際は、以下のようなマニフェストファイルを書いてkubectl applyすれば、毎日指定した時間に削除を実行してくれます。
apiVersion: batch/v1 kind: CronJob metadata: name: mastodon-delete-old-remote-cache namespace: mastodon spec: schedule: '0 22 * * *' # UTC 22時、JSTだと毎日7時 jobTemplate: spec: backoffLimit: 0 template: spec: containers: - name: delete-old-remote-cache image: tootsuite/mastodon imagePullPolicy: IfNotPresent command: - /bin/sh - -c - bin/tootctl media remove --days=90' # 90日よりも古いメディアファイルを削除 envFrom: - configMapRef: name: mastodon-config - secretRef: name: mastodon-secret restartPolicy: OnFailure startingDeadlineSeconds: 120 concurrencyPolicy: Replace successfulJobsHistoryLimit: 1 failedJobsHistoryLimit: 1
CronJobで定期的に削除するようにしましたが、Mastodonはv4.0.0からWebの管理画面からリモートメディアの保持期間を設定できるようになり、期限切れのメディアは勝手に削除されるようになったため、CronJobで削除する必要はなくなりました。
ただ、私はBetterUptimeのHeartbeat Monitorを使って定期削除が定期的に動いているかを監視しているため、今後もCronJobで定期削除を動かし続けようかなと思っています。
運用面では、他にもマニフェストファイルをArgoCDで管理することで、Mastodonのバージョンアップ時の作業がyamlをgit pushするだけになり、前よりも楽になりました。
sublimer.hatenablog.com
おわりに
MastodonをKubernetes上でどのようにして動かしているのかを簡単に紹介しました。
現在はそれなりには動いているのですが、時々コンテナへのlivenessProbeが失敗してPodが再起動する事象が起きています。
複数あるPodが一斉に再起動しており、原因は謎です。
再起動はすぐに完了するため影響はほとんど無いのですが、できれば直したいなーと思っています。
他にも、Horizontal Pod Autoscaler等を活用していい感じにスケールさせる仕組みも導入したいと思っています。
あとは可用性の向上もやってみたいなーと思っています。
せっかくKubernetesを使うようにしたので、KubernetesのNodeをパブリッククラウドにも置いて、ハイブリッドクラウド構成にすることなどを考えています。
この辺は追々やっていくかもしれません。
最後に余談ですが、今回この記事に載せるインフラ構成図は、d2というツールで作ってみました。
github.com
いい感じの図をシュッと作れるのでとても良かったです。
Fediverse Advent Calendar 2022、明日もお楽しみに!!